Il metodo di previsione probabilistica, un miglioramento sostanziale per la gestione del rischio associato alla generazione da fonti rinnovabili
I metodi di previsione puntuale consistono nello stimare un unico valore come risultato atteso di una variabile nel futuro. Si tratta dell’approccio più comune in molte applicazioni, poiché fornisce una cifra concreta e di facile interpretazione.
Ad esempio, nel settore energetico, un modello di produzione eolica può prevedere che la generazione sarà di 35 MWh in un’ora specifica. Il suo principale vantaggio è la semplicità, che ne facilita l’utilizzo nei processi decisionali operativi.
Tuttavia, un grande svantaggio è che non riflette l’incertezza della previsione, il che può portare a errori significativi se le condizioni che influenzano la produzione cambiano in modo imprevisto.
D’altra parte, i metodi di previsione probabilistica non forniscono un singolo valore, bensì una distribuzione di probabilità dei possibili risultati, permettendo di quantificare l’incertezza del modello predittivo. Invece di stimare che la generazione eolica sarà esattamente di 35 MWh, un modello probabilistico potrebbe indicare che c’è un 80% di probabilità che si collochi tra 30 e 40 MWh

Il modello probabilistico come approccio chiave per la gestione del rischio
Le decisioni operative basate su distribuzioni predittive possono generare benefici maggiori rispetto a quelle che si basano esclusivamente su previsioni puntuali.
Sebbene la loro implementazione e analisi siano più complesse, risultano fondamentali in settori in cui la gestione del rischio è cruciale, come l’energia, la meteorologia e la finanza.
In questo contesto, i modelli probabilistici producono una distribuzione dei risultati accompagnata da probabilità assegnate, il che consente di:
- Migliorare sostanzialmente la gestione del rischio considerando molteplici scenari.
- Progettare strategie di trading che ottengono risultati economici migliori in contesti di incertezza.
Conformal Prediction: misurare l’incertezza
È importante sottolineare che il semplice fatto che le previsioni indichino probabilità associate non implica necessariamente che gli intervalli di previsione siano calibrati e validi per rappresentare il rischio nell’uso dei sistemi di forecasting.
Per questo, è necessario integrare negli algoritmi di previsione tecniche che permettano di generare intervalli di previsione validi in termini di copertura empirica su campioni finiti.
Conformal Prediction (CP) è una metodologia che consente di generare intervalli di previsione con garanzie di validità, senza la necessità di assumere una distribuzione specifica dei dati in ingresso. Il suo principale vantaggio è che fornisce garanzie formali di copertura per qualsiasi livello di confidenza, rendendolo uno strumento particolarmente interessante per la previsione probabilistica nel settore energetico.
Nell’esperienza di Gnarum, il CP si è affermato come un paradigma di calibrazione molto prezioso per conferire affidabilità ai sistemi di forecasting.
Le sue caratteristiche principali sono:
- Flessibilità: non richiede ipotesi sulla distribuzione dei dati.
- Agnosticismo: può essere applicato a qualsiasi tipo di modello predittivo, dalle regressioni lineari alle reti neurali profonde.
- Adattabilità: attraverso l’implementazione di strategie di calibrazione adeguate a ciascun caso d’uso, è possibile regolare dinamicamente l’ampiezza degli intervalli di previsione in funzione del comportamento dei modelli di previsione puntuale sottostanti.

Metriche di valutazione
Per validare un sistema di previsione probabilistica è necessario calcolare metriche sia relative alla precisione puntuale, sia alla validità e alla nitidezza degli intervalli di previsione.
Tra le diverse possibilità di selezione dei KPI, di seguito si specificano le metriche principali per la verifica di un sistema di forecasting con queste caratteristiche.
1. Previsioni puntuali
Le metriche utilizzate per valutare la precisione puntuale di un modello o sistema possono essere classificate in due grandi gruppi, in base alla norma matematica utilizzata per calcolare l’errore: metriche basate sulla norma L1 e metriche basate sulla norma L2.
Norma L1
Le metriche basate sulla norma L1 si fondano sul valore assoluto degli errori tra i valori stimati e i valori reali osservati.
- Sono meno sensibili ai valori anomali (outliers).
- Facilitano un’interpretazione intuitiva, poiché misurano l’errore nelle stesse unità dei dati originali.
- L’indicatore di riferimento di questo gruppo è il MAE (Mean Absolute Error) – Errore assoluto medio
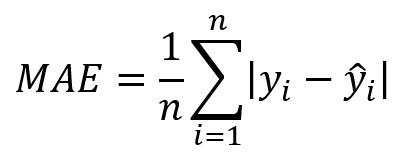
Norma L2
Le metriche associate alla norma L2 si basano sull’errore quadratico medio e sono spesso espresse nelle unità originali applicando la radice quadrata della media degli errori quadratici.
- Penalizzano maggiormente gli errori di grande entità.
- Sono sensibili ai valori anomali (outliers).
- L’indicatore di riferimento di questo gruppo è il RMSE (Root Mean Squared Error) – Radice quadrata dell’errore quadratico medio.
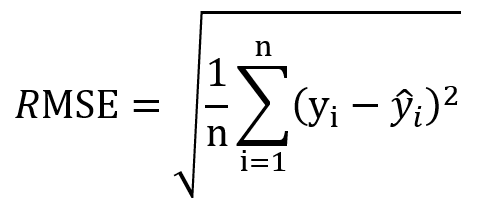
2. Previsioni probabilistiche
Indici di copertura
- Copertura nominale: si definisce come il livello di confidenza previsto dal modello per un intervallo di previsione. Ad esempio, un valore dell’80% per l’intervallo P10–P90 significa che, teoricamente, il valore reale dovrebbe trovarsi all’interno di tale intervallo nell’80% dei casi.
- Copertura empirica: si calcola come il rapporto di osservazioni reali che ricadono all’interno dell’intervallo di previsione.

- Se la copertura empirica risulta inferiore alla copertura nominale, ciò implica che gli intervalli sono troppo stretti, sottovalutando l’incertezza delle previsioni fornite dal sistema predittivo.
- Se, al contrario, è superiore, il modello sta sovrastimando l’incertezza reale del sistema predittivo, risultando quindi eccessivamente conservativo.
Prova di copertura
Per validare la calibrazione del modello, si utilizza abitualmente il test di Kupiec.
Questo test di ipotesi, basato sulla distribuzione chi-quadrato, è una prova statistica fondamentale nella valutazione dei modelli di rischio, in particolare nel contesto del Value-at-Risk (VaR).
Si basa sull’idea di confrontare la frequenza osservata di eventi estremi o “eccezioni” con la frequenza teorica attesa in base al livello di confidenza definito. In altre parole, il test verifica se il modello prevede correttamente il numero di volte in cui viene superata una soglia di rischio, fenomeno noto come copertura incondizionata.
- Un p-value alto indica che la copertura empirica è compatibile con quella nominale, suggerendo che il modello è ben calibrato.
- Un p-value basso indica che la copertura non è statisticamente valida, il che può segnalare problemi di calibrazione o di adeguatezza del modello.
La valutazione della copertura consente di validare che le code della distribuzione probabilistica, ad esempio, la coppia P10–P90 corrispondente a un livello di confidenza dell’80%, siano valide in termini di quantificazione dell’incertezza.
Lunghezza media dell’intervallo di previsione
Una volta calibrati gli intervalli di previsione, l’incertezza del sistema predittivo in un determinato periodo è rappresentata dalla lunghezza media degli intervalli di previsione, calcolata come la differenza tra i limiti superiore e inferiore dell’intervallo stimato:
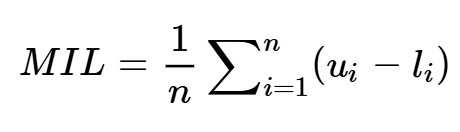
Dove:
- ui: limite superiore dell’intervallo di previsione.
- li: limite inferiore dell’intervallo di previsione.
Winkler Score
Il Winkler Score è una metrica integrata progettata per valutare la qualità degli intervalli di previsione.
Combina in un’unica misura sia la valutazione della lunghezza dell’intervallo, sia una penalizzazione nel caso in cui il valore osservato si trovi al di fuori dei limiti dell’intervallo di previsione.
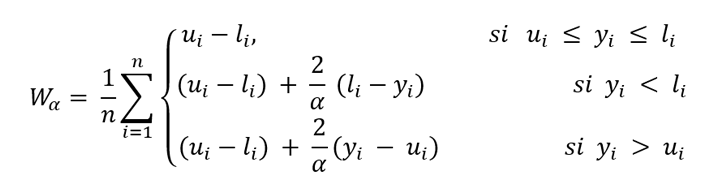
Dove:
- li: limite inferiore dell’intervallo di previsione.
- ui: limite superiore dell’intervallo di previsione.
- yi = valore reale osservato..
- α è il livello di significatività dell’intervallo di previsione (1-α, è il livello di confidenza).
- Gli intervalli che non contengono il valore reale vengono penalizzati con un fattore proporzionale a 2⁄α rispetto alla distanza tra yi e il limite più vicino dell’intervallo di previsione [li,ui ].
Quanto più basso è il Winkler Score, migliore è la valutazione dell’algoritmo, poiché indica intervalli più stretti e precisi.
- Per una corretta gestione del rischio, è necessario includere negli algoritmi tecniche che permettano di quantificare l’incertezza in modo accurato, come il Conformal Prediction (CP)).
- Inoltre, è fondamentale verificare che le tecniche di calibrazione siano state applicate correttamente, utilizzando metriche di valutazione come il Winkler Score.
In questo contesto, Gnarum offre un servizio di forecasting probabilistico basato su tecniche come il Conformal Prediction, calibrate in modo ottimale grazie a una validazione continua mediante le metriche precedentemente descritte.
Gnarum vanta un’esperienza consolidata nell’implementazione di servizi di previsione probabilistica, in particolare nel campo della previsione fotovoltaica e dell’energia eolica, sia on-shore che off-shore.
La previsione eolica, per sua natura altamente variabile, rappresenta una delle sfide più complesse nel settore delle energie rinnovabili. Per questo motivo, richiede modelli robusti, ben calibrati e in grado di fornire intervalli di confidenza rigorosi.
La competenza di Gnarum in questo ambito si è consolidata attraverso anni di sviluppo tecnico, validazione costante e partecipazione a benchmark europei insieme ai migliori fornitori del mercato.

Gnarum partecipa attivamente come fornitore ufficiale in ambienti multiprovider con i TSO europei, dove vengono integrate diverse fonti di previsione per la valutazione dell’energia gestita nei vari nodi della rete.
Questo approccio combinato di forecasting probabilistico, basato su tecniche di Conformal Prediction, consente a Gnarum di offrire soluzioni robuste, affidabili, trasparenti e adattate alle sfide del mercato energetico attuale, in particolare in contesti ad alta incertezza.